NBA Player Financial Analysis
Let's dive into it!

Theory
NBA teams often make multi-million dollar decisions based on player performance, yet salary allocations don't always reflect on-court value. I wanted to explore this imbalance using real data from the 2024–25 season, aiming to identify over- or underpaid players using a data-driven approach.


Goal
My goal was to build a fully automated data pipeline that collects player statistics and salary data, calculates performance-based value metrics, and delivers interactive visual insights. The system needed to refresh every 4 hours, ensuring timely updates throughout the season.
Workflow
-
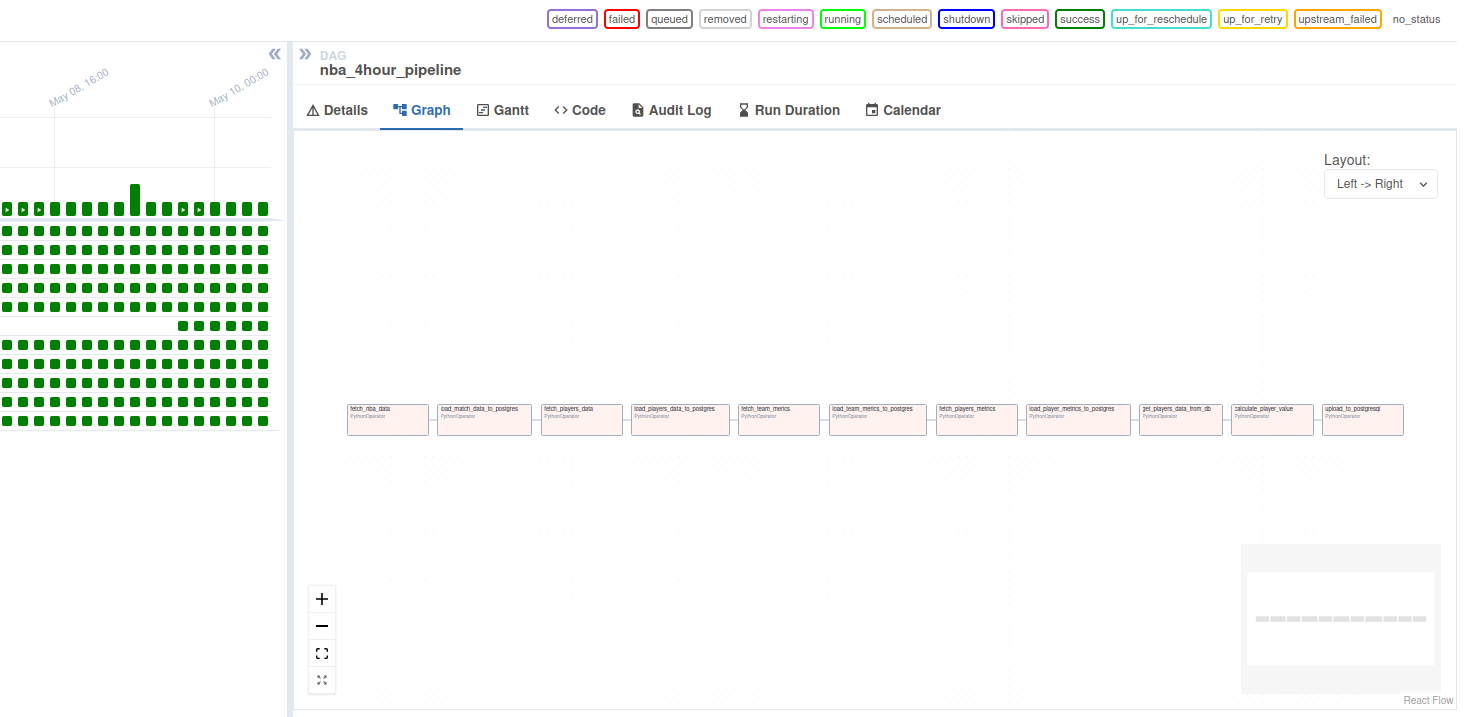
Collected player and team data from the
nba_apiand used Python to preprocess and clean the data (including name normalization and standardization of team abbreviations) and load to a PostgreSQL database. - Implemented local caching with Pickle to avoid hitting NBA API rate limits.
- Web scraped salary data and merged it with performance stats.
- Engineered key metrics such as Player Value Average, Value per Dollar, and Value % of Team, using Pandas for feature creation.
- Orchestrated the full ETL pipeline using Apache Airflow, scheduled to run every 4 hours.
- Designed interactive dashboards in Apache Superset to visualize and explore player value trends by team or individual.
Conclusion
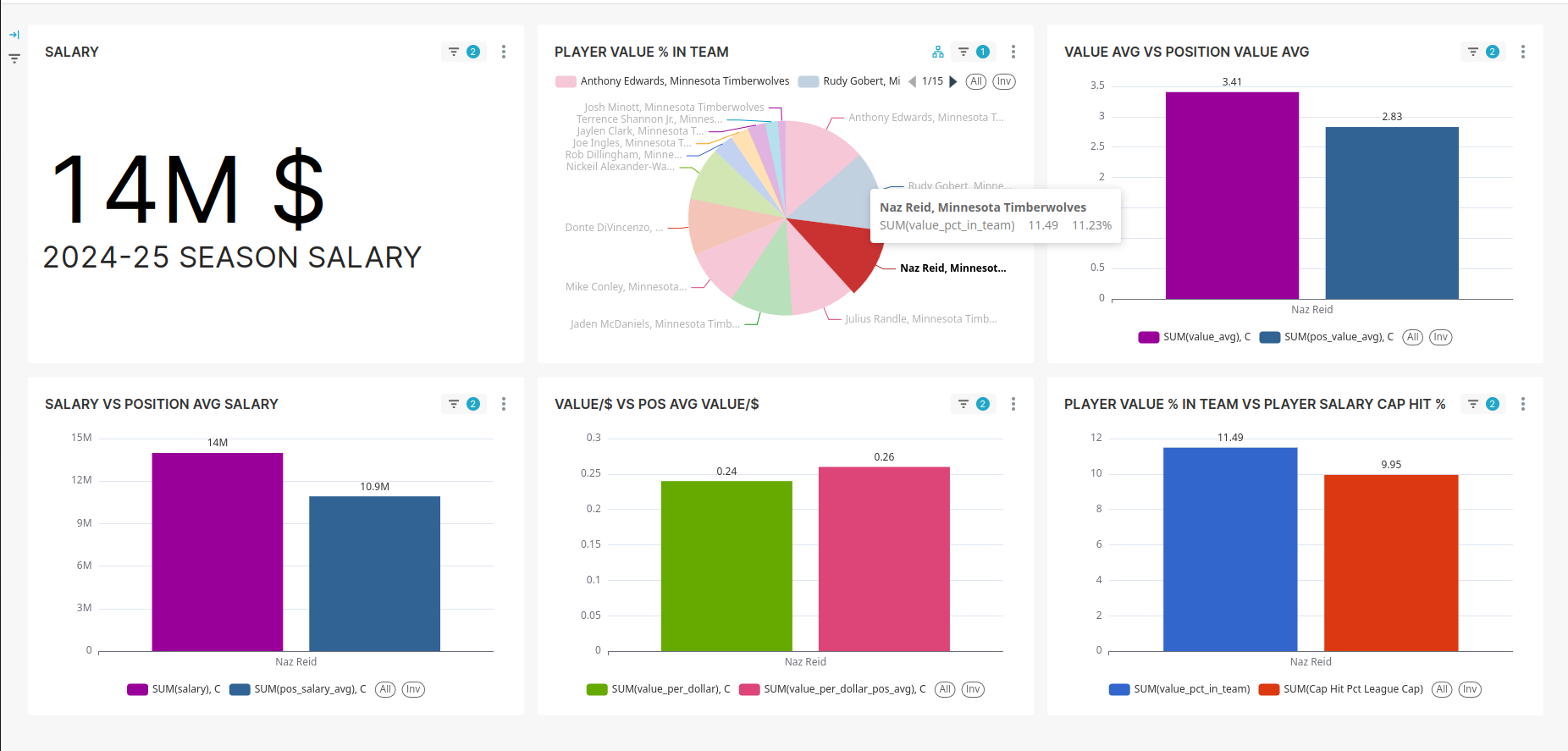
The pipeline now automatically updates every 4 hours, generating a reliable dataset for NBA player valuation. It provides actionable insights, such as identifying undervalued players like Naz Reid, whose contributions exceed their salary share. The interactive Superset dashboards allow filtering by team and player, enabling users to explore patterns in value efficiency across the league.
Contact Info
- Location: 4220 Hajdúböszörmény,Hungary
- LinkedIn: Attila Kormos